

Esempio 2 – Apprendimento non supervisionato clustering
Esempio 2 – Apprendimento non supervisionato clustering
Diversamente dall’apprendimento supervisionato, la clusterizzazione non supervisionata (clustering) costruisce modelli a partire da dati non appartenenti a classi predefinite (non esiste attributo target).Consideriamo il seguente dataset
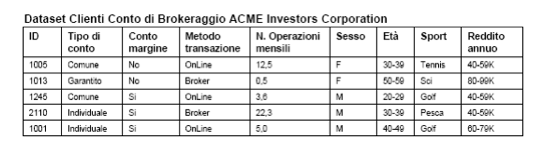
Supponiamo di voler utilizzare un approccio di data mining per mettere in evidenza eventuali schemi (pattern) all’interno dei dati della tabella precedente.
Potremmo innanzitutto porci le seguenti domande:
- E’ possibile delineare un profilo generale di investitore online: In caso affermativo, quali caratteristiche distinguono un investitore online da uno che utilizza un broker:
- E’ possibile determinare se un nuovo cliente che inizialmente non apre un conto margine lo aprirà in futuro:
- E’ possibile creare un modello in grado di predire accuratamente il numero medio di transazioni mensili per un nuovo investitore:
- Quali caratteristiche differenziano un investitore da un’investitrice:
Ognuna di queste domande è candidata per un approccio di tipo supervisionato, perché ciascuna di esse definisce un attributo i cui valori rappresentano un insieme di classi di output predefinite.
Nel primo caso, metodo di transazione, nel secondo conto margine, nel terzo numero operazioni mensili, nel quarto sesso.
La difficoltà che sta dietro la clusterizzazione è la difficoltà di stabilire l’affinità. La clusterizzazione serve se poi posso attribuire un contenuto informativo al fatto che una certa popolazione attribuisce a un cluster.
Però, potremmo anche porci le seguenti domande:
- Quali attributi simili permettono di raggruppare i clienti della ACME Investors:
- Quali differenze nel valore degli attributi segmentano il database dei clienti:
Si tratta di domande candidate per un approccio di clusterizzazione non supervisionata. Molti di questi sistemi richiedono una stima iniziale del numero di cluster, altri utilizzano un algoritmo per determinare in modo efficace tale numero. In entrambi i casi, il sistema di clusterizzazione cerca di raggruppare i dati in cluster di interesse significativo.
Supponiamo di aver sottoposto i dati della ACME Investors ad un modello di clusterizzazione non supervisionata e di aver ottenuto i seguenti cluster:
1. IF conto margine = Si AND età = 20-29 AND reddito annuo = 40-59K THEN Cluster = 1 (accuratezza = 0,80; copertura = 0,50)
2. IF tipo di conto = Garantito AND sport preferito = sci AND reddito annuo = 80-99K THEN Cluster = 2 (accuratezza = 0,95; copertura = 0,35)
3. IF tipo di conto = Comune AND operazioni mensili > 5 AND metodo di transazione = online THEN Cluster = 3 (accuratezza = 0,82; copertura = 0,65)
I cluster sono rappresentati da regole del tutto simili a quelle viste per la classificazione. Otteniamo regole produttive che consentono di capire se si presenta un nuovo cliente a quale cluster appartiene. Anche queste regole hanno delle metriche di qualità che sono ancora l’accuratezza (confidenza) e la copertura.
I valori di accuratezza e copertura forniscono importanti informazioni, in particolare:
- ACCURATEZZA : in che percentuale la condizione conseguente sarà verificata essendo soddisfatte le condizioni antecedenti;
- COPERTURA : percentuale di casi nel cluster che soddisfano le condizioni antecedenti.
- A tale proposito, se consideriamo la regola 1 possiamo dire che la condizione di appartenenza al Cluster 1 sarà verificata nell’80% dei casi in cui sono soddisfatte le tre condizioni antecedenti. Analogamente, il 50% di casi nel Cluster 1 soddisfa le tre regole antecedenti.
Le regole sviluppate hanno un contenuto di conoscenza di portata variabile.
Ad esempio, la regola del Cluster 1 può non essere una sorpresa, dal momento che gli investitori più giovani con un reddito medio-alto presentano tradizionalmente un atteggiamento più spregiudicato nei confronti degli investimenti.
Anche la regola del Cluster 3 non è propriamente una nuova scoperta, mentre quella del Cluster 2 può invece considerarsi inaspettata e, quindi, utile nel processo decisionale.
La ACME Investors Corporation potrebbe trarre vantaggio da questa scoperta investendo risorse finanziarie per sponsorizzare conti garantiti per figli e/o nipoti in riviste dedicate allo sci.
Continua a leggere:
- Successivo: Quanto il data mining è adatto a risolvere un problema
- Precedente: Esempio 1 – apprendimento supervisionato
Per approfondire questo argomento, consulta le Tesi:
- Un analisi statistica su come le recensioni possono influenzare la scelta di acquisto dei consumatori
- Sistemi web-based di analisi strategica: Business Intelligence e Big Data
- Il Data mining a supporto dei processi decisionali in azienda
- L'evoluzione dei sistemi informativi e di controllo aziendali
- Analisi dei processi di CRM nel web: electronic customer relationship management
Puoi scaricare gratuitamente questo appunto in versione integrale.
 Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.
Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.
Login
Oppure utilizza il tuo account
 o
o
