
Esempio 1 – apprendimento supervisionato
Esempio 1 – apprendimento supervisionato
Albero decisionaleGli alberi di classificazione stanno all’interno degli alberi decisionali. Gli alberi decisionali sono composti anche dagli alberi di regressione.
Consideriamo il seguente dataset.
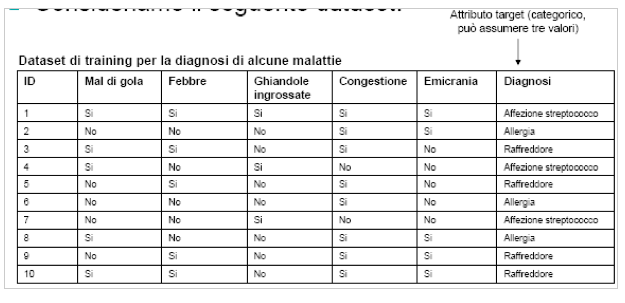
La diagnosi è di tipo categorico. Si parte sempre da una serie di informazioni riferite al passato.
Esistono tre classi:
- affezione da streptococco,
- allergia,
- raffreddore.
E’ possibile identificare una regola ch identifica la diagnosi in funzione del valore assunto dai singoli attributi: Vogliamo costruire un modello generale, per fornire un modello di ausilio al medico per facilitare la diagnosi.
Supponiamo di voler creare un modello generale per rappresentare i dati presenti in tabella, con l’obiettivo di applicarlo successivamente a dati (di pazienti) per i quali l’attributo target (diagnosi) non sia noto.
Un albero decisionale è una struttura semplice in cui i nodi non terminali rappresentano i test di uno o più attributi, i rami rappresentano il risultato dei test (valore) e i nodi terminali (o foglie) rappresentano le decisioni risultanti.
Vantaggi dell’approccio: gli alberi decisionali sono facili da interpretare, possono essere trasformati in regole e hanno dimostrato di ottenere buoni risultati.
Albero decisionale costruito a partire dal dataset di training.
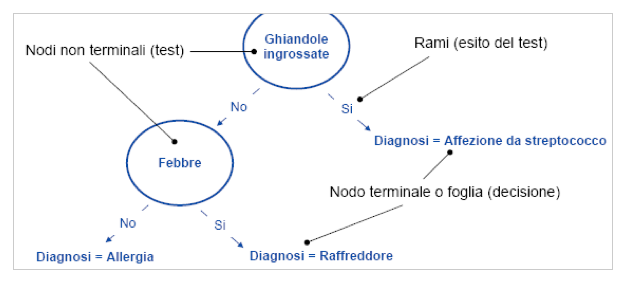
Il nodo è un attributo. Lo prendo e inizio a costruire l’albero da questo attributo. Si costruiscono i rami a partire dal nodo iniziale, che sono i valori assunti dall’attributo. Dalla tabella vedo che tutte le osservazioni per le quali le ghiandole ingrossate portano ad un’affezione da streptococco mi permette di individuare un nodo terminale o foglia.
Se invece l’attributo ghiandole ingrossate vale no, vediamo che sono distribuite tra allergie e raffreddore, non sono arrivata a una foglia. Vado quindi a cercare di separarle rispetto al valore di un altro attributo, per esempio febbre. Si costruisce così un altro nodo. Si arriva così a determinare altre foglie.
L’albero così costruito (vedremo in seguito gli algoritmi più noti per la costruzione di alberi decisionali) ci consente di classificare correttamente tutti i casi del training set.
Da ciò si evince che gli attributi mal di gola, congestione e emicrania non giocano un ruolo fondamentale nella formulazione di una diagnosi.
Normalmente, l’albero viene verificato con un secondo dataset (test set) di dati di test (per i quali i valori dell’attributo target sono noti), prima di rilasciarlo in produzione.
A questo punto, possiamo utilizzare l’albero per classificare i seguenti casi (con diagnosi non nota).
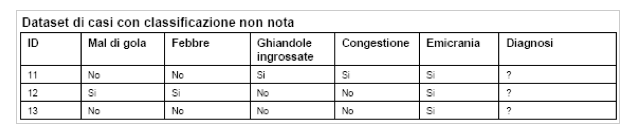
Considerando i soli attributi ghiandole ingrossate e febbre, è facile vedere che i pazienti ID = 11 e ID = 12 appartengono rispettivamente alle categorie affezione da streptococco e raffreddore.
E’ possibile tradurre qualsiasi albero decisionale in un insieme di regole di classificazione (o regole produttive), aventi la forma:
IF condizioni antecedenti
THEN condizioni conseguenti
In particolare, l’albero creato può essere descritto dalle seguenti tre regole:
1. IF ghiandole ingrossate = Si
THEN diagnosi = affezione da streptococco
2. IF ghiandole ingrossate = No AND febbre = Si
THEN diagnosi = raffreddore
3. IF ghiandole ingrossate = No AND febbre = No
THEN diagnosi = allergia
Data la regola IF antecedente, THEN conseguente
Si introducono le seguenti metriche di qualità:
- SUPPORTO : la percentuale di osservazioni nel data set che soddisfano la condizione precedente
- CONFIDENZA : nell’insieme delle osservazioni che soddisfano antecedente, la percentuale di quelle che soddisfano conseguente
- COPERTURA :nell’insieme delle osservazioni che soddisfano conseguente, la percentuale di quelle intercettate dalla regola
Queste sono importanti informazioni di qualità della classificazione.
Utilizziamo ora le regole produttive per classificare il paziente ID = 13.
Poiché la variabile ghiandole ingrossate è uguale a No, ignoriamo la prima regola. Analogamente, poiché la febbre è assente, ignoriamo anche la seconda regola. Infine, poiché entrambe le condizioni antecedenti per la terza regola sono soddisfatte, possiamo concludere che il paziente presenta una allergia.
In questo esempio ci siamo basati su un’analisi pre efettuata, in realtà quando si costruisce un albero decisionale c’è un primo problema che è quello di capire da quale attributo dobbiamo partire per costruire l’albero, vado a vedere come si ripartiscono le osservazioni, costruisco dei nodi, devo decidere l’algoritmo da utilizzare e infine eliminare le foglie inutili.
Un altro problema grosso degli alberi di classificazione è l’adattamento, ossia non bisogna adattare troppo l’albero di classificazione dal data set, perché se l’albero dipinge con estrema precisione le caratteristiche del data set, potrebbe non essere utile quando c’è un data set che si discosta un po’ da quello di riferimento.
Continua a leggere:
- Successivo: Esempio 2 – Apprendimento non supervisionato clustering
- Precedente: Metodologie di analisi: apprendimento supervisionato
Per approfondire questo argomento, consulta le Tesi:
- Un analisi statistica su come le recensioni possono influenzare la scelta di acquisto dei consumatori
- Sistemi web-based di analisi strategica: Business Intelligence e Big Data
- Il Data mining a supporto dei processi decisionali in azienda
- L'evoluzione dei sistemi informativi e di controllo aziendali
- Analisi dei processi di CRM nel web: electronic customer relationship management
Puoi scaricare gratuitamente questo appunto in versione integrale.
 Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.
Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.