
Esempio di albero decisionale
- I dati del training set provengono da
una compagnia di assicurazioni, nella quale un esperto del dominio
applicativo ha assegnato ad ogni utente un livello di rischio (A = Alto,
B = Basso) basandosi su esperienze precedenti e incidenti
effettivamente avvenuti.
- Supponiamo che il training set sia il seguente, dove:
S = Vettura Sportiva
FA = Vettura Familiare
AU = Autocarro
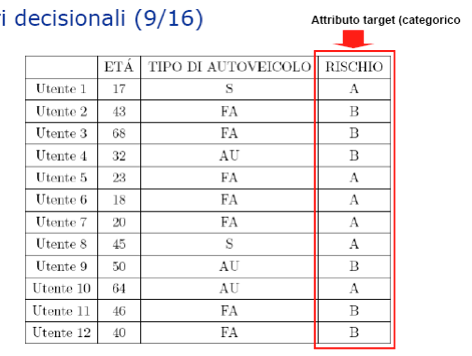
Gli attributi predittori sono:
- età;
- tipo di autoveicolo.
Il rischio è l’attributo target.
È possibile identificare alcune semplici regole che consentono di attribuire una classe di appartenenza:
La compagnia vorrebbe sviluppare una procedura automatica che sia in
grado di segnalare se un nuovo cliente può essere rischioso.
Si tratta di un problema tipico di classificazione, che può essere risolto con la costruzione di un albero decisionale.
Applichiamo l’algoritmo C4.5 (qui presentato in una versione semplificata) al training set.
1. Il training set T è dato.
2. Selezioniamo l’attributo età (assumendo, in questa fase, che sia
quello che meglio differenzia le osservazioni e riducendolo a due soli
valori = 23 e > 23 mediante una trasformazione che descriveremo
meglio in seguito).
3. Abbiamo così creato il nodo iniziale e i primi due rami dell’albero: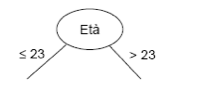
3. Rispetto ai valori dell’attributo, il training set si ripartisce in
due sottoclassi, di cui la prima (età = 23) soddisfa uno dei criteri
predefiniti (rischio = alto).
Abbiamo così creato un nodo terminale (o foglia).
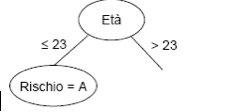
La seconda sottoclasse non soddisfa i criteri predefiniti ed esistono
altri attributi per effettuare un’ulteriore suddivisione del percorso
dell’albero. Torniamo quindi al passo 2.
2. Selezioniamo l’attributo Tipo di Autoveicolo.
3. La sottoclasse età > 23 si ripartisce in tre ulteriori sottoclassi
(S, FA, AU) ognuna delle quali soddisfa uno dei criteri predefiniti o
non ci sono alternative.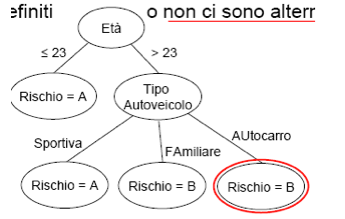
3. Si tratta di nodi terminali (o foglie) dal momento che tutte le
sottoclassi generate soddisfano i criteri predefiniti o non ci sono
alternative. La costruzione è terminata.
Per purezza si intende quante osservazioni stanno all’interno della
classe. L’ultimo nodo non è puro (no 100%) perché non tutte le
osservazioni stanno all’interno della classe di appartenenza.
I nodi rappresentano le combinazioni di attributi presenti, i rami i
risultati dei test effettuati sui nodi, le foglie il risultato della
classificazione.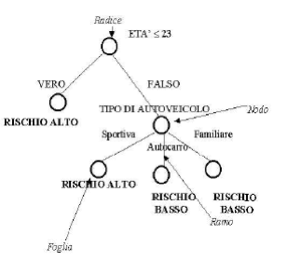
Abbiamo già visto che la rappresentazione grafica dell’albero
corrisponde ad una sequenza di regole di classificazione basate sul
costrutto IF condizioni antecedenti THEN condizioni conseguenti.
Nel nostro caso, la sequenza di regole generate è: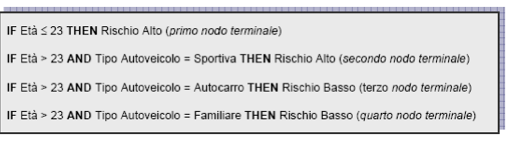
Regole che possono essere raggruppate come segue:
Come abbiamo già osservato, nello sviluppo dell’esempio è stato
applicato un metodo di riduzione dei dati (che riprenderemo), noto come
discretizzazione (applicabile sia ad attributi continui che categorici).
In particolare, il valore dell’attributo Età è stato ridotto a due sole
classi, = 23 e > 23.
Continua a leggere:
- Successivo: Criteri per la costruzione degli alberi decisionali - controllo della crescita
- Precedente: Definizione di alberi decisionali
Per approfondire questo argomento, consulta le Tesi:
- Un analisi statistica su come le recensioni possono influenzare la scelta di acquisto dei consumatori
- Sistemi web-based di analisi strategica: Business Intelligence e Big Data
- Il Data mining a supporto dei processi decisionali in azienda
- L'evoluzione dei sistemi informativi e di controllo aziendali
- Analisi dei processi di CRM nel web: electronic customer relationship management
Puoi scaricare gratuitamente questo appunto in versione integrale.
 Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.
Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.